False Positives Are a Revenue Leak, Not a Security Metric
Every fraud rule you tighten kills real revenue. Here's how to think about false positives as a P&L problem, not a security dashboard number.
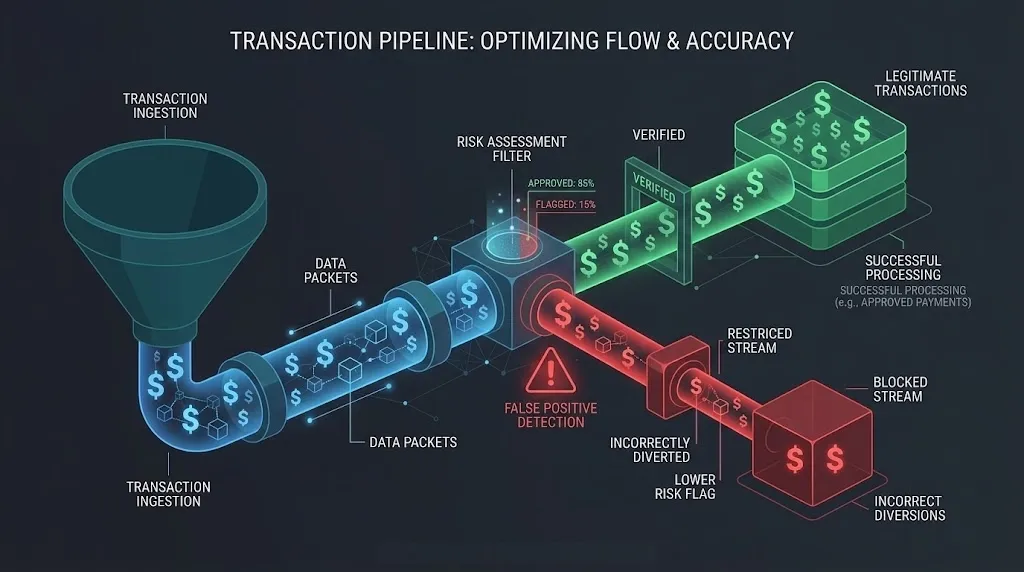
A fraud analyst's inbox is full of blocked transactions. Their dashboard shows a 0.3% fraud rate. The security team is celebrating.
Meanwhile, the finance team is staring at a different number: 4.2% of all transactions were declined by fraud rules. At a company processing $100M annually, that's $4.2M in blocked revenue. A significant portion of those declines are legitimate customers who gave up and went to a competitor.
Nobody celebrates that number.
The Math Nobody Does
Most fraud teams measure:
- Fraud rate: Percentage of transactions that are actually fraudulent
- Detection rate: Percentage of fraud caught by the system
- False negative rate: Fraud that slipped through
Almost nobody measures the revenue cost of false positives — legitimate transactions that were wrongly blocked.
Here's the math:
Monthly transactions: 1,000,000
Average transaction value: $85
Fraud rule decline rate: 4.2%
Declined transactions: 42,000
Estimated false positive %: 60% (industry average for aggressive rules)
False positives: 25,200
Recovery rate: 15% (customers who retry and succeed)
Lost customers: 21,420
Revenue lost: $1,820,700 / month
That's almost $22M annually in lost revenue from over-aggressive fraud rules. And this doesn't count the lifetime value of customers who never come back.
Compare that to the fraud you're preventing. If your actual fraud rate is 0.3% and average fraud value is $200, you're preventing about $600K in fraud annually.
You're spending $22M to save $600K.
This math is why I treat false positives as a P&L problem, not a security metric.
Why Fraud Rules Ratchet Toward Aggression
Fraud rules only tighten. They almost never loosen. Here's the cycle:
- A new fraud pattern emerges.
- The fraud team adds a rule to catch it.
- The rule catches the fraud. It also blocks some legitimate transactions.
- Nobody measures the legitimate declines.
- Another fraud pattern emerges. Another rule.
- Repeat for three years.
After three years, you have 200 rules. Some contradict each other. Some target fraud patterns that no longer exist. The false positive rate has crept from 1% to 5% and nobody noticed because each individual rule "works."
This is technical debt in fraud systems. And unlike code debt, it silently drains revenue every day.
Thinking About It Differently
The right framework isn't "how much fraud did we catch?" It's "what is the total cost of our fraud operation?"
Total fraud cost = Fraud losses + False positive revenue loss + Operational cost
Where:
Fraud losses = fraud that slipped through × average fraud amount
FP revenue loss = false positives × average transaction value × (1 - recovery rate)
Operational cost = manual review team + tools + infrastructure
This reframes the question. A fraud team that catches 95% of fraud but blocks 5% of legitimate transactions might be more expensive than a team that catches 85% of fraud but blocks only 1% of legitimate transactions.
| Scenario | Fraud caught | Fraud loss | FP rate | FP revenue loss | Total cost |
|---|---|---|---|---|---|
| Aggressive | 95% | $30K/mo | 5.0% | $3.6M/mo | $3.63M/mo |
| Balanced | 90% | $60K/mo | 2.0% | $1.4M/mo | $1.46M/mo |
| Optimized | 85% | $90K/mo | 0.8% | $570K/mo | $660K/mo |
In most businesses, the "optimized" approach — catching less fraud but blocking far fewer legitimate customers — is the cheapest option by a massive margin.
The Manual Review Trap
When fraud teams recognize the false positive problem, the first instinct is: "Let's add manual review for borderline cases."
This creates a different problem.
Manual review queues don't scale. Every human reviewer handles maybe 200 cases per day. At 42,000 declines per month, you need a team of reviewers working full-time just to handle the borderline cases.
And manual review adds latency. A customer whose transaction is "under review" for 4 hours doesn't wait. They go somewhere else and never come back.
Manual review is a band-aid. The real fix is better signals.
Better Signals, Not More Rules
I've learned that fraud detection quality comes from signal richness, not rule quantity.
A system with 200 rules and poor signals is worse than a system with 20 rules and rich signals.
Rich signals include:
Behavioral signals:
- Time between deposit and action (the 15-second window)
- Session navigation patterns
- Form completion speed and patterns
Historical signals:
- Customer lifetime history (2 years of clean transactions = high trust)
- Device trust score (this specific device has completed 50 successful transactions)
- Merchant category history (customer regularly buys from this type of merchant)
Contextual signals:
- Time of day relative to user's normal activity
- Geographic consistency
- Transaction amount relative to user's personal average
With rich signals, you can set high-confidence thresholds. Block only when multiple signals align. Let borderline transactions through if the customer has strong history.
The result: fewer rules, fewer false positives, and — counterintuitively — better fraud detection.
The Organizational Problem
This isn't just a technical problem. It's an organizational one.
Fraud teams are measured on fraud prevention. They're rewarded for catching fraud. They're punished when fraud slips through.
Nobody gets fired for blocking a legitimate customer. Someone absolutely gets fired when a fraud pattern goes uncaught.
This incentive structure guarantees over-aggressive rules. The fraud team is optimizing for their metric, not the company's P&L.
The fix is organizational:
- Shared metrics: The fraud team should own both the fraud rate AND the false positive revenue impact. Both numbers on the same dashboard.
- Revenue attribution: Every declined transaction should be tagged with the rule that declined it. Calculate the revenue impact of each rule monthly.
- Rule sunset process: Every rule should have a review date. If a rule hasn't caught real fraud in 90 days, it needs justification to stay active.
- Cross-functional review: Product, finance, and fraud should review the total fraud cost quarterly — not just the fraud loss number.
What I Do Now
In every system I build, the fraud pipeline produces two outputs:
- The decision (allow / review / block)
- The cost estimate of that decision
Decision: BLOCK
Rule: velocity_3_deposits_10min
Confidence: 0.72
Estimated fraud risk: $200
Estimated FP cost: $85 (avg transaction) × 0.40 (FP probability) = $34
Net expected value of blocking: $200 × 0.72 - $34 = $110
→ Block is justified
Decision: BLOCK
Rule: new_device_high_value
Confidence: 0.31
Estimated fraud risk: $150
Estimated FP cost: $150 (transaction) × 0.85 (FP probability) = $127.50
Net expected value of blocking: $150 × 0.31 - $127.50 = -$81
→ Block is NOT justified, downgrade to monitoring
Every blocking decision has an expected value calculation. If the expected value of blocking is negative — meaning you'll lose more money from false positives than you'll save from prevented fraud — the system downgrades to monitoring instead of blocking.
This isn't soft on fraud. It's smart about revenue.
Fraud prevention is not about catching everything. It's about catching the right things without burning revenue. Every fraud rule has a cost. If you're not measuring that cost, you're not managing fraud — you're just building an increasingly expensive wall that blocks customers and fraudsters alike.
Measure both sides. Optimize for total cost. Your CFO will thank you.